Alright, so I was cruising reddit the other day and found a python script that mines through your comment history and pulls all that information into a text file. I immediately did so. One small downside of this is that only the last three months of comment history are stored for access from your comment history page (the rest being archived into a different database, or different section of the same database), so this is just a snapshot of three months of comments. Once I had the text file, I stripped out all the metadata that the script put in, stripped out all the URLs I had linked in comments, and started on trying to see what I could do with this corpus.
Let’s get the boring statistics out of the way: the corpus contains 378,294 characters and 67,979 words. The Fleisch-Kinkaid Grade level is 11 (that is, the corpus as a whole is understandable only if you’ve reached 11th grade), while the Flesch-Kincaid Reading Ease score is 52 (fairly difficult, good for those at the end of high school).
Top Five three word phrases:
- “a lot of” – 50 times
- “be able to” – 37 times
- “one of the” – 34 times
- “I don’t think” – 29 times (possibly there because I like to contradict people)
- “problem is that” – 27 times
Top Five four word phrases:
- “in the first place” – 16 times
- “the problem is that” – 13 times
- “aabb aabb aabb aabb” – 10 times (this comes from me making Punnett squares)
- “would be able to” – 8 times
- “is going to be” – 8 times
Here’s a word cloud of my most commonly used words (generated with the help of Wordle):

From that, you can see that “people” is my most commonly used word. Note that the word could excludes the most commonly used words in the English language; for fun, here’s a table which compares my use of those words to that of the Brown corpus:
| Brown Corpus | My Reddit Comment Corpus |
|---|---|
| THE | THE |
| OF | TO |
| AND | THAT |
| TO | A |
| A | OF |
| IN | AND |
| THAT | IS |
| IS | I |
| WAS | IT |
| HE | IN |
| FOR | YOU |
For fun, I ran it through a parts-of-speech tagger which has about a 97% success rate; here’s a table that shows the various categorizations and frequencies of speech. I’ll skip past the part where I had to enter a bunch of information into a spreadsheet and just show you the colorful pie chart:
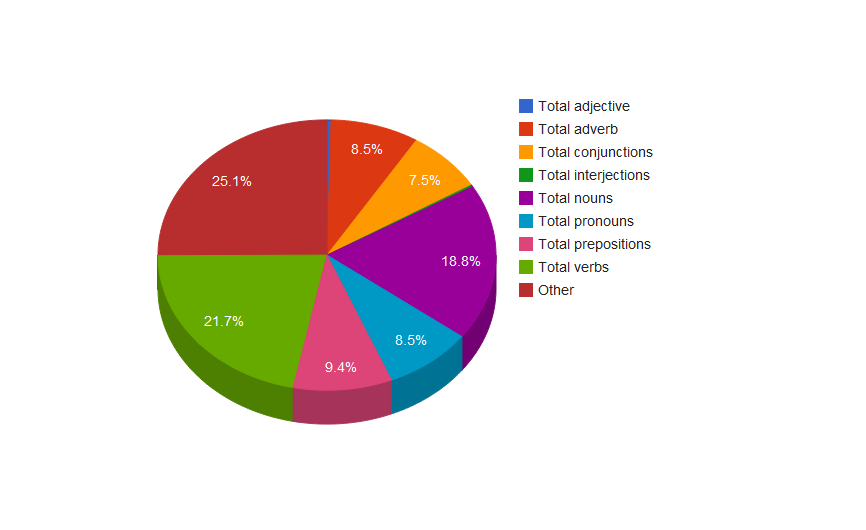
You have to admit that it is quite colorful. Go on, click to make it larger; I’ll wait. It’s not shown there, but the verbs BE, DO, and HAVE make up about 30% of the total verb usage. Verbs (and nouns) used have a Pareto distribution, (with BE at the head of the tail) which is quite hard to show in a meaningful way, and usually doesn’t tell you a lot more than simply knowing that it’s long-tail distributed.
I may add a second part onto this post later which does some actual analysis, but first I have to read a couple of linguistics papers and see how the above data deviates from normal (if it does). Then I’d have to make some conclusions about what that actually means, if anything.
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
Data-Mining My Reddit Comment History
3 thoughts on “Data-Mining My Reddit Comment History”
How can I do this with my reddit comment history? I'm not a computer whiz but I can figure most things out!
1. Go to http://pastebin.com/j1QxzKiR and copy-paste that script into notepad++ then save it as "whatever.py".
2. Download Python 2.x from someplace like http://www.python.org/getit/releases/2.7/ and then install it.
3. Run the python file from the command line (see here: http://mail.python.org/pipermail/tutor/2004-July/030634.html) and input your username.
4. This will create a file called "username".txt (for example, keltranis.txt or I_RAPE_CATS.txt), but might take some time – just let it run until it's done.
5. Now that your comment history is saved as a .txt file, go into Notepad++ and strip out all of the stuff that is not part of your actual commenting. This is the hard part, because you have to learn a bit of the context stuff. This was of great help: http://markantoniou.blogspot.com/2008/06/notepad-how-to-use-regular-expressions.html
That's about it. Then you just run it all through Excel and make some charts.
http://www.redditgraphs.com/